For a better value proposition to the reader, I’ll leapfrog to NULL handling after a small introduction to SQL.
PL/SQL stands for Procedural Language/Structured Query Language. It is a Fourth Generation Computer Language (4GL). In simpler terms, it means it’s one step closer to spoken human language than a 3GL (say, C / C++, Java etc.). All vendors comply with ISO (1987) and ANSI (1986) SQL standards fundamentally but have extensions that show variations in Date and Time syntax, String concatenation, NULL handling, and Comparison case sensitivity.
Be aware of variations in SQL ISO and ANSI standards’ extentions when porting from one database appliance to another.
I will endeavor to note behavior variations in Oracle, IBM PureData System for Analytics (Netezza), and MySQL. Oracle SQL too conforms to SQL:2016, but is not identical. For example – it lacks TIME data type and has DATE and TIMESTAMP instead. Also, you might be surprised to know that standards don’t define INDEX at all. Hence, its creation and physical implementation vary as well. In fact, it’s absent altogether in IBM PureData System for Analytics (Netezza).
Oracle SQL conforms to SQL:2016, but is not identical. For example – it lacks TIME data type and has DATE and TIMESTAMP instead.
Also, you might be surprised to know that standards don’t define INDEX at all. Hence, its creation and physical implementations vary. In fact, it’s absent altogether in IBM PureData System for Analytics (Netezza).
The NULL
In SQL’s Three Valued Logic, NULL is the ‘Unknown’. This is actually a pretty cool, and simple, concept which leads to a lot of confusion in implementation. Here is a compilation of what I have learned about NULL handling in code.
A NULL is ¯\_(ツ)_/¯! You don’t know what it is, so it is nothing. If someone mixes an unknown (in other words, NULL) quanity of sugar in your coffee, would you know how sweet it will be? Any operation involving NULL will result in NULL.
- Primary Key cannot have NULL values.
- Foreign Key can have NULL values. It is a legitimate design decision for a foreign key relationship to be optional, and the way to represent that is by making the referencing FK optional, i.e. allowing NULLs. If you don’t want the foreign key relationship to be optional, specify NOT NULL constraint in addition to the FK constraint.
- If NULL is an argument in any expression, the expression will result in NULL.
- You cannot use an equality = operator to equate NULLs, because it’s impossible to compare two unknown quantities. Hence, instead of = operator, IS NULL and IS NOT NULL functions are used to identify null and non-null values
- A column with a UNIQUE constraint applied to it can contain only one entry of NULL value. It cannot have multiple NULL rows.
- Most scalar functions return null when given a null argument. Unless they are specifically meant for handling NULLs like NVL or DECODE or COALESCE.
- NULL occurrences are ignored in the input data set by all aggregate functions, with exception of COUNT (*) and GROUPING.
- If the input data set contains no rows, or contains rows only containing NULLs as arguments to any aggregate function, then the function returns NULL. The exception is COUNT, it can never return a NULL. If no input data set, then COUNT (column name or alias or position indicator or *) will return a 0. For rows with only NULLs, COUNT (column name or alias or position indicator) will return a 0 and COUNT (*) will return the row count.
- GROUP BY puts NULLS all together in the Unknown bucket and so groups all NULL values in a single group/row set. DISTINCT also does the same.
- In ORDER BY, NULL is randomly assigned a value. In Oracle and Netezza, it’s the ‘highest value’, so in ASC order it’s placed last. In MySQL, it’s assigned the ‘least value’.
- NULL handling when a sub-query runs on empty tables or its result set contains zero records –
- A scalar subquery returns NULL to parent query.
- A multiple row subquery, using ANY/SOME, will be evaluated as FALSE.
- A multiple row subquery, using ALL, will be evaluated as TRUE!
- NULL handling when a sub-query’s result set consists of NULLs only –
- A scalar subquery returns NULL to parent query.
- A multiple row subquery, using ANY/SOME, will be evaluated as FALSE.
- A multiple row subquery, using ALL, will be evaluated as FALSE.
- In DECODE, two NULL values are considered to be ‘token equivalent’. NULL compared to NULL will produce a TRUE result and send the corresponding value back. This is Oracle and Netezza behavior. MySQL’s DECODE is used for a different purpose entirely – it is used to decode encrypted strings.
- In CASE, two NULL values are NOT considered to be ‘token equivalent’. NULL compared to NULL will produce a FALSE result.
- IN and NOT IN operators will not ‘match’ a NULL, as expected. If a subquery is expected to return a NULL, then maybe choose to work with EXISTS and NOT EXISTS. EXISTS and NOT EXISTS evaluate presence/absence of rows returned rather than actual value comparisons done by IN and NOT IN.
- Remember, we don’t know what a NULL is. And if we don’t know what it is, we cannot consider two NULLs to be the same. Hence, an inner JOIN will never match and return NULL. You need to do an outer join to get the NULL records.
- When filtering Outer Join Result Set, the filtering condition should be part of the ‘ON’ clause using the ‘AND’ operator and not the WHERE clause.
Let’s review this statement using a LEFT OUTER JOIN scenario. We know that a LEFT OUTER JOIN returns all records from the Left Hand Side table and only the matched records from the Right Hand Table. Thus, the result set can potentially have NULL entries for Right Hand Side table columns for an unmatched condition. Now, if you want to filter out records in the result set from the Right Hand Side table, a filter condition on the Right Hand Table column in WHERE clause will filter out NULLs as well, effectively reducing the OUTER JOIN to INNER JOIN. A similar filter condition using ‘AND’ with the ‘ON’ clause would have returned the NULL records as well as the records matching the condition.We’ll talk more about this later.
For now, let’s have some examples.
A blank cell denotes an empty string.
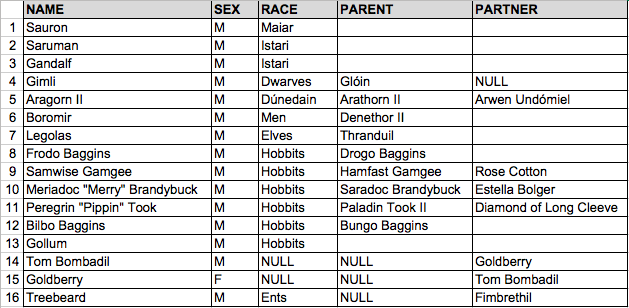

Aggregate Function Example:- SELECT COUNT(*), COUNT(PARENT) FROM T_GENEALOGY; COUNT(*) COUNT(PARENT) 16 13 Had the table been empty, the result would have been: COUNT(*) COUNT(PARENT) 0 0
DECODE and CASE Example (Note - DECODE performs a different function in MySQL):-
SELECT
NAME
, DECODE (PARENT, NULL, 'UNKNOWN',PARENT) AS DECODE_PARENT_NM
, CASE PARENT
WHEN IS NULL THEN 'UNKNOWN'
ELSE '-'
END AS CASE_PARENT_NM
FROM T_GENEALOGY WHERE NAME IN ('Tom Bombadil', 'Goldberry');
NAME DECODE_PARENT_NM CASE_PARENT_NM
Tom Bombadil UNKNOWN -
Goldberry UNKNOWN -
Join Example :- SELECT A.NAME, A.RACE , B.CREATOR FROM T_GENEALOGY A INNER JOIN T_CREATOR B ON A.RACE = B.RACE; This query's result set will have 14 rows. Tom Bombadil and Goldberry records will be ABSENT as NULL values cannot be matched. Thus,it's considered a bad idea to populate NULLs in frequently joined columns. SELECT A.NAME, A.RACE , B.CREATOR FROM T_GENEALOGY A LEFT OUTER JOIN T_CREATOR B ON A.RACE = B.RACE; This query's result set will have 16 rows. Tom Bombadil and Goldberry records will be present as they are part of Left Hand Side table.
